
实验九
时间序列处理与应用
知识点
- 时间序列
- SARIMA
- 线性回归
- XGBoost
- Prophet
时间序列数据介绍
-
定义:
时间序列指的是同一个统计指标的数值按其发生的时间先后顺序排列而构成的一组数列
-
处理工具:Statsmodule 模块
-
在将数据加载至 Pandas 数据表时,可以通过
pandas.read_csv()的parse_dates=关键字参数指定需要被解析为时间字段的列名
预测质量评价指标
-
- 取值范围在
sklearn.metrics.r2_score调用
- 取值范围在
-
- 所有单个观测值与算术平均值的偏差的绝对值的平均
- 具有可解释性,取值范围在
sklearn.metrics.mean_absolute_error
-
- 所有单个观测值与算术平均值的偏差的绝对值的中值,对异常值不敏感
- 取值范围为
sklearn.metrics.median_absolute_error
-
- 最常用的度量标准,对大偏差给予较高的惩罚,反之亦然
- 取值范围为
sklearn.metrics.mean_squared_error
-
- 对均方差取对数而得到,更重视小偏差,通常用在呈指数趋势的数据
- 取值范围为
sklearn.metrics.mean_squared_log_error
-
平均绝对百分比误差,取值范围为
平移、平滑、评估
移动平均(MA)
假设
Pandas 提供了 DataFrame.rolling(window).mean() 接口用于实现移动平滑
加权平滑
将
指数平滑
指数平滑 则是一开始加权所有可用的观测值,而当每一步向后移动窗口时,进行指数地减小权重
函数的递归中隐藏了指数:也就是每次乘以
双指数平滑
其中,
人工设置部分参数组合可能绘制出奇奇怪怪的结果,需要考虑引入自动参数调节。
三指数平滑
又称为 Holt-Winters 模型。相比于双指数平滑,三指数平滑还增加了季节性成分。如果时间序列预计没有季节性,就不应该使用这种方法。
模型引入了 Brutlag 方法,用来创建置信区间:
其中,
时间序列交叉验证
-
要评估模型,必须选择适合该任务的损失函数(描述了模型拟合数据的接近程度);
-
使用交叉验证,将损失函数值最终降至全局最小值
- 时间序列具有时间结构,不能随意对数据进行组合
- 随机组合会导致观测点之间的所有时间依赖关系将丢失
-
将时间序列数据划分为多个时间片段,每次选取一段或多段进行训练,并使用下一段进行测试。
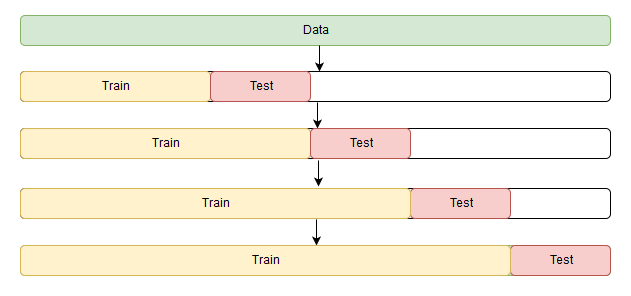
Sklearn 提供了 sklearn.model_selection.TimeSeriesSplit 实现时间序列的划分,它会返回一组由 (train_indices, text_indicies) 组成的索引集合。
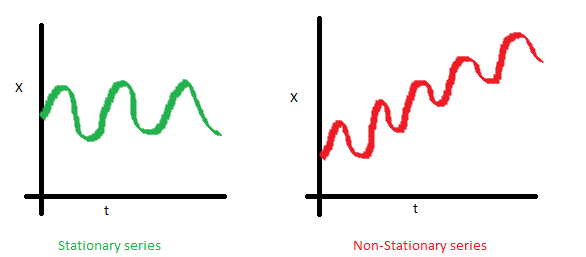
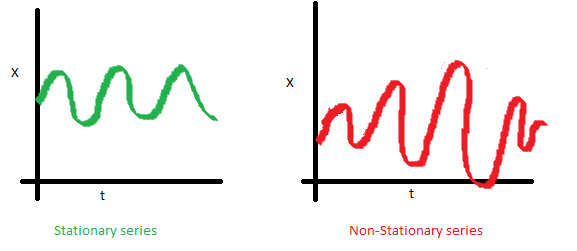
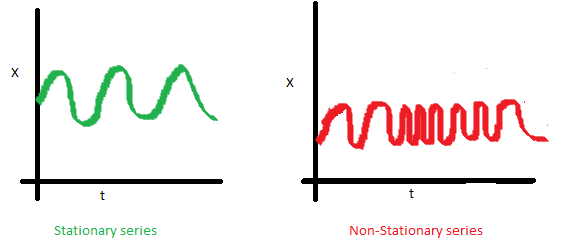
平稳性
平稳性 通常指的是时间序列是否平稳,其统计特性(均值、方差以及协方差)是否随时间变化。
-
均值不稳定性
-
方差不稳定性
-
协方差不稳定性
对于标准高斯噪声
在达到临界值后,序列
若能够使用
非平稳性消除方法
- 多阶差分
- 移除趋势和季节性去除
- 平滑
- Box-Cox 转换
- 对数转换
摆脱非平稳性并构建 SARIMA
SARIMA
季节性差分自回归滑动平均模型(Seasonal Autoregressive Integrated Moving Average,记为 SARIMA)是常用的时间序列预测分析方法之一,它可以对任何周期的时间序列进行建模。
SARIMA 的部分参数需要根据自相关图和偏自相关图来进行选取,其中相关性一般用 皮尔逊系数 来衡量。
ARIMA
-
-
-
-
综上所属,ARIMA 模型将有3个参数:
-
-
-
时间序列上的线性模型
- 一些模型永远不会被认为是「随时可用」的
- 需要太多的时间进行数据准备
- 需要对新数据进行频繁的再训练
- 很难调优
- 选择几个特性,构建简单的 LR 或 RF 会更加容易
特征提取
- 时间序列相邻记录的时差
- (滑动)窗口统计
- 最大/小值
- 中位数和平均数
- 方差
- 时间节点特征
- 年、月、日,时、分、秒
- 节假日、特殊日期(需要日历辅助)
- 目标编码
- 其他模型导出的结果
目标编码
- 许多机器学习算法并不能直接处理类别型数据,要将类别型特征转化为数值型特征
- 在时间序列中,可以考虑使用 平均值编码
正则化和特征选择
- Ridge(L2)正则化:均方误差损失+正则化项,正则化项对系数平方进行惩罚
- Lasso(L1)正则化:对系数绝对值惩罚
XGBoosting
- 这是一种梯度提升方法
- 基于树的模型处理数据趋势的能力较差,而 XGBoost 的基模型是决策树
- 必须先消除时间序列数据的趋势,或者使用一些特殊的技巧
- 使用线性模型来预测趋势,然后将其加入 XGBoost 的预测
Prophet
- 由 Facebook 开源
- 有许多直观且易于解释的定制功能,以供逐步改善模型预测的质量
- 适用对象和场景很广泛
Prophet 预测模型
本质上是一个加性回归模型:
其中,
-
-
-
-
趋势
-
非线性饱和增长模型(逻辑增长模型):
其中,
-
简单分段线性模型:增长率恒定、适合不存在饱和的线性增长数据
季节性
- 每周的季节性数据是通过虚拟变量来进行建模的,产生6个虚拟变量(不包括周日)
- 年季节性通过傅里叶级数进行建模
- v0.2 之后加入了新的日季节性特性,可以使用日以下尺度的时序数据,并做出日以下尺度的预测
假期和事件
- 可以预测特殊时间节点
- 需要提供自定义的事件列表
误差
- 表示的是所构建的模型中未反映的信息
- 一般取高斯噪声
与其他算法的对比

- Naive 模型:一个过度简化的预测方法,仅仅根据上一时间点的观测数据来预测所有未来值
- S-Naive 模型:考虑了季节性因素,与 Naive 类似
- Mean 模型:使用数据的平均值作为预测
- ARIMA 模型:自回归集成移动平均
- ETS 模型:指数平滑
安装
Prophet 支持 Python API 与 R API
数据集
- 文章数量数据集 ,使用制表符分隔;
- 数据集来自 Medium.com ,此站点于 2012年8月15日 起对外提供服务;
可视化分析数据
Plotly 是一个自带交互功能、用于机器学习和高级数据分析的绘图库。
构建预测模型
Prophet 提供 API 与 scikit-learn 提供的 API 非常相似:
- 创建一个
Prophet()模型对象; - 调用
fit()方法学习优化模型; - 调用
make_future_dataframe()方法生成需要预测的未来时间序列; - 调用
predict()方法进行预测。
Prophet 的官方建议至少根据最新的几个月的历史数据来做出预测,理想情况下是一年以上。
- Prophet 有内置可视化工具(
.plot()方法)评估模型结果 .plot_components()方法用于可视化模型不同特征的预测结果
预测结果质量评估
Prophet 在执行 predict() 时,除了给出预测值 yhat 之外,还会给出与预测结果相关的其他评估指标。
可视化
Prophet 可能不适合方差不稳定的时间序列,至少在使用默认设置时是这样。
Box-Cox 变换
这是一个单调的数据转换,可以用来稳定方差。
 微信支付
微信支付 USDT-TRC20
USDT-TRC20